Tabla de Contenidos
Kubernetes: configuración con Docker en Debian 12
Introducción a Kubernetes
Kubernetes es una plataforma de código abierto diseñada para la automatización del despliegue, escalado y gestión de aplicaciones en contenedores. Su arquitectura permite agrupar de manera inteligente los contenedores que componen una aplicación en unidades lógicas, facilitando su gestión y descubrimiento. Un clúster de Kubernetes se compone fundamentalmente de un Control Plane y uno o más Nodos Worker. El Plano de Control es responsable del estado global del clúster y de la orquestación, albergando componentes como el Servidor API, etcd, el Planificador (Scheduler) y el Gestor de Controladores (Controller Manager). Por otro lado, los Nodos Worker son las máquinas donde se ejecutan las cargas de trabajo de las aplicaciones, cada uno con un Kubelet, Kube-proxy y un tiempo de ejecución de contenedores.
Es fundamental aclarar el papel de Docker en las configuraciones modernas de Kubernetes. Desde la versión 1.22, Kubernetes ya no utiliza directamente Docker Engine como su tiempo de ejecución de contenedores principal. En su lugar, Kubernetes interactúa con tiempos de ejecución de contenedores que cumplen con la Container Runtime Interface (CRI). Docker Engine, de hecho, incluye containerd, que es un tiempo de ejecución robusto, estándar de la industria y compatible con CRI. Por lo tanto, al instalar Docker Engine, se instala efectivamente containerd, que es el componente que Kubernetes utilizará para gestionar los contenedores. Esta distinción es vital para comprender la arquitectura subyacente y para una resolución de problemas efectiva.
La razón detrás de esta aclaración radica en la evolución de Kubernetes. Originalmente, Docker Engine era el tiempo de ejecución predeterminado, pero la tendencia en el desarrollo de Kubernetes ha sido hacia una CRI estandarizada, que abstrae los motores de contenedores específicos. Esto significa que, si bien las herramientas de Docker (como docker build para crear imágenes) siguen siendo muy relevantes, el componente de tiempo de ejecución dentro de Kubernetes es containerd. Esta distinción es crucial para una configuración correcta y estable, ya que gestiona las expectativas del usuario y evita posibles confusiones durante la resolución de problemas; por ejemplo, por qué docker ps podría no mostrar directamente los pods gestionados por Kubernetes.
Desarrollada por Google, permite orquestar contenedores en múltiples hosts. Con Kubernetes, se puede configurar el balanceo de carga entre contenedores y ejecutar varios contenedores en múltiples sistemas.
Es compatible con servidores físicos locales, OpenStack, y nubes públicas como Google, Azure, AWS, y otras.
Características
Kubernetes le ofrece amplia funcionalidad, a saber:
- Descubrimiento de servicios y balanceo de carga. Kubernetes puede exponer un contenedor usando el nombre DNS o su propia dirección IP. Si el tráfico hacia un contenedor es alto, Kubernetes puede balancear la carga y distribuir el tráfico de red para que la implementación sea estable.
- Orquestación de almacenamiento. Kubernetes le permite montar automáticamente el sistema de almacenamiento que prefiera, como almacenamiento local, proveedores de nube pública, etc.
- Implementaciones y reversiones automatizadas. Puede describir el estado deseado para sus contenedores implementados con Kubernetes, que puede cambiar el estado actual al deseado a un ritmo controlado. Por ejemplo, puede automatizar Kubernetes para crear nuevos contenedores para su implementación, eliminar los existentes y adaptar todos sus recursos al nuevo contenedor.
- Empaquetado automático de contenedores. Usted proporciona a Kubernetes un cluster de nodos que puede usar para ejecutar tareas en contenedores. Le indica a Kubernetes cuánta CPU y RAM necesita cada contenedor. Kubernetes puede integrar contenedores en sus nodos para optimizar sus recursos.
- Autorreparación. Kubernetes reinicia los contenedores que fallan, los reemplaza, elimina los que no responden a la comprobación de estado definida por el usuario y no los anuncia a los clientes hasta que estén listos para funcionar.
- Gestión de secretos y configuración Kubernetes le permite almacenar y gestionar información confidencial, como contraseñas, tokens OAuth y claves SSH. Puede implementar y actualizar secretos y la configuración de la aplicación sin reconstruir las imágenes de sus contenedores ni exponerlos en la configuración de su pila.
- Ejecución por lotes. Además de los servicios, Kubernetes puede gestionar sus cargas de trabajo por lotes y de CI, reemplazando los contenedores que fallan, si lo desea.
- Escalado horizontal. Escale su aplicación hacia arriba y abajo con un simple comando, con una interfaz de usuario o automáticamente según el uso de la CPU.
- Doble pila IPv4/IPv6. Asignación de direcciones IPv4 e IPv6 a pods y servicios.
- Diseñado para la extensibilidad. Añada funciones a su cluster de Kubernetes sin modificar el código fuente.
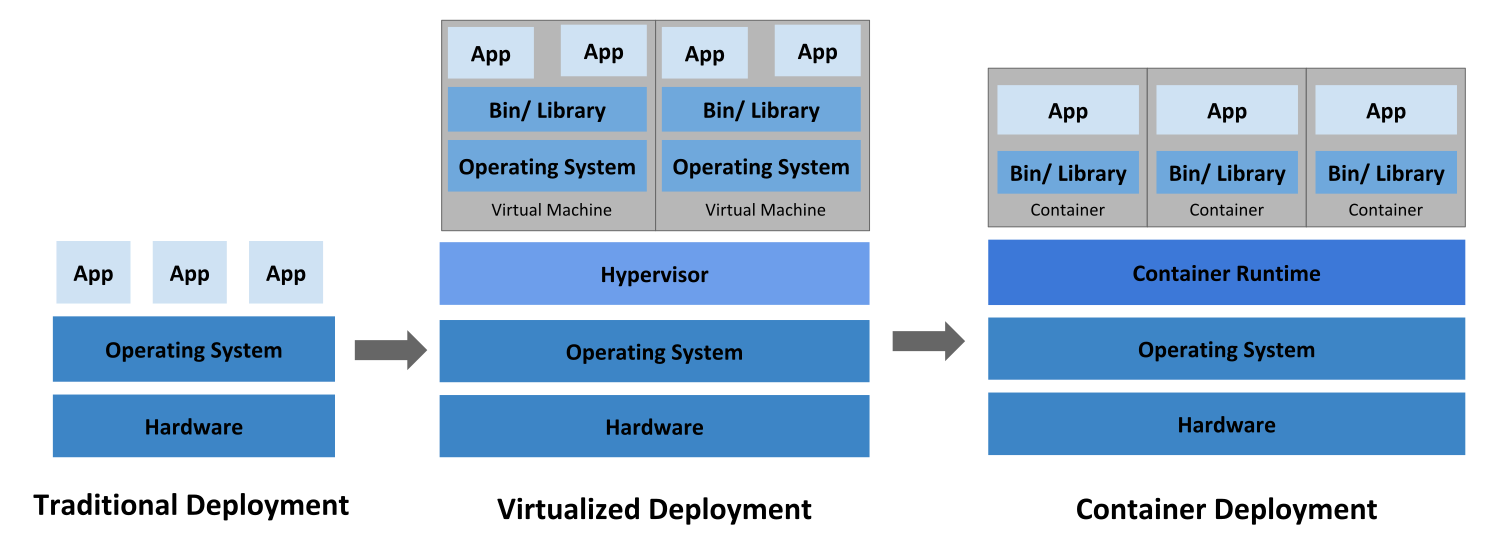
Figura 1. Evolución histórica de la virtualización
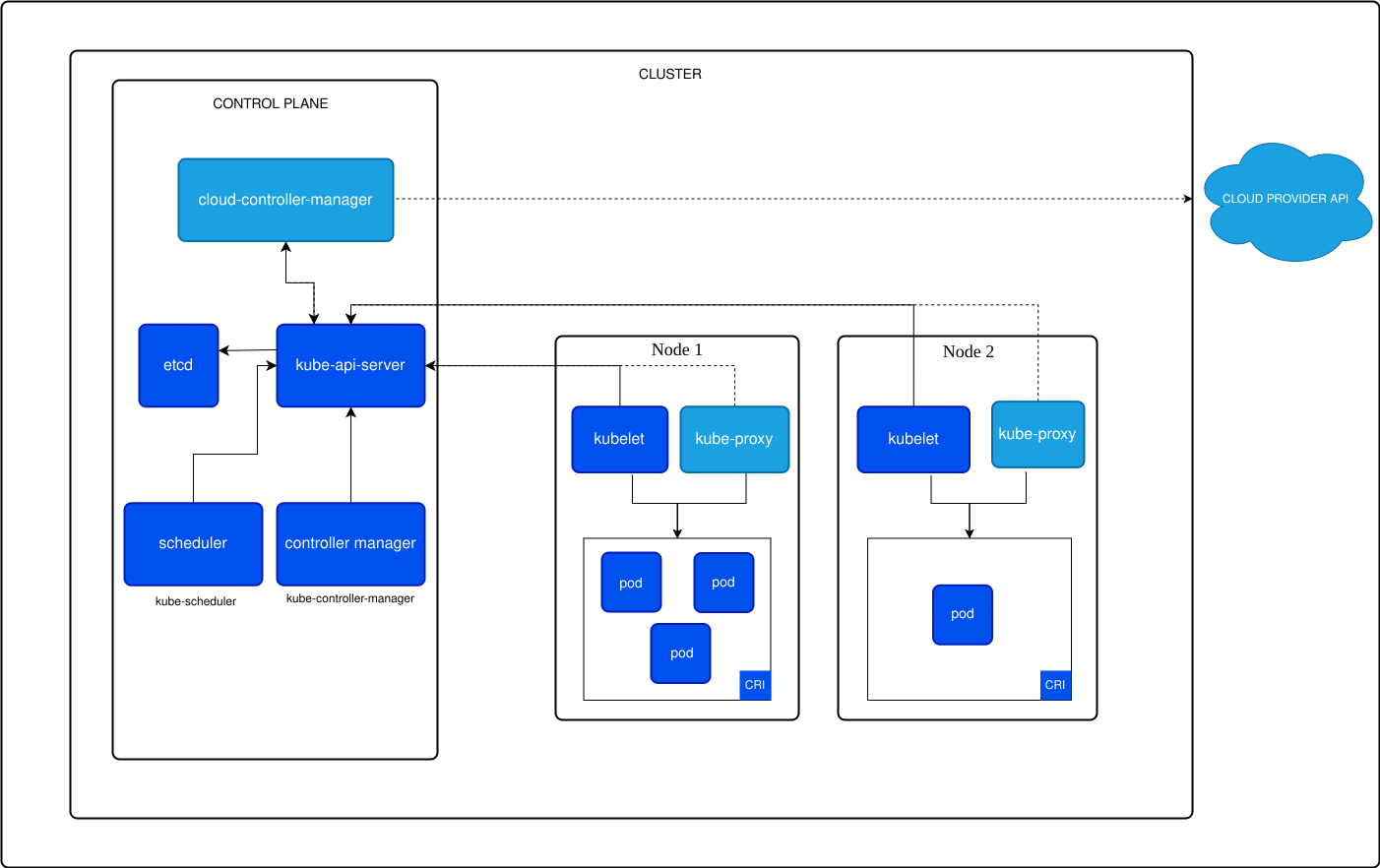
Figura 2. Componentes de un cluster Kubernetes
I. Requisitos del sistema y preparación inicial
Antes de proceder con la configuración de Kubernetes, es imperativo asegurar que el sistema Debian 12 cumpla con los requisitos mínimos y esté adecuadamente preparado. Recomendaciones de Hardware (CPU, RAM, Almacenamiento, Red)
La elección del hardware es un factor crítico que influye directamente en la estabilidad y el rendimiento del clúster de Kubernetes.
Requisitos mínimos para un nodo de Kubernetes (Control plane y Worker)
- RAM: Se requieren 2 GB o más de RAM por máquina. Una cantidad inferior dejará muy poco espacio para las aplicaciones, lo que conducirá a una degradación significativa del rendimiento
- CPUs: Se necesitan 2 CPUs o más para las máquinas del plano de control. Los nodos worker pueden funcionar con menos, pero generalmente se recomiendan 2 o más para cualquier carga de trabajo significativa.
- Red: Es indispensable una conectividad de red completa entre todas las máquinas del clúster (una red pública o privada es aceptable). Esto es fundamental para la comunicación entre nodos y entre pods
- Identificadores: Cada nodo debe poseer un nombre de host, dirección MAC y product_uuid únicos
Especificaciones recomendadas para clústeres pequeños (por ejemplo, Desarrollo/Pruebas)
- Nodo Master: Se recomienda priorizar al menos 8 GB de RAM y una CPU de múltiples núcleos. Esto asegura operaciones más fluidas del plano de control, especialmente para etcd
- Nodo Worker: Se aconsejan al menos 4 GB o más de RAM por nodo worker
- Almacenamiento: Aunque un SSD SATA de 120 GB es suficiente para un pequeño clúster de prueba de Kubernetes, un SSD NVMe con mayores IOPS es fuertemente recomendado para un mejor rendimiento de etcd y una mayor capacidad de respuesta general del plano de control. El rendimiento de etcd es crucial para la estabilidad del clúster
- Red: Se aconseja una conexión Gigabit Ethernet para una red fluida y eficiente dentro del clúster
- Fiabilidad: Para configuraciones que simulan entornos del mundo real, se debe asegurar una fuente de alimentación fiable y considerar soluciones de almacenamiento redundantes para la estabilidad de etcd
La distinción entre los requisitos “mínimos” y “recomendados” de hardware no se limita a asegurar una funcionalidad básica, sino a lograr un clúster utilizable y de alto rendimiento, incluso para despliegues a pequeña escala. Adherirse únicamente a los mínimos puede generar cuellos de botella significativos en el rendimiento, afectando particularmente a etcd (el almacén de clave-valor del clúster y fuente de la verdad) y dejando recursos insuficientes para las aplicaciones reales. Esta orientación proactiva ayuda a evitar problemas comunes que resultan en clústeres lentos o inestables, que a menudo son difíciles de diagnosticar a posteriori.
A continuación, se presenta una tabla que resume los requisitos del sistema:
| Categoría | Requisito Mínimo (Por Nodo) | Recomendado (Para Clústeres Pequeños) | Notas/Consideraciones |
|---|---|---|---|
| CPU | 2 CPUs o más (Plano de Control) | Multi-núcleo | - |
| RAM | 2 GB o más | 8 GB+ (Master), 4 GB+ (Worker) | Menos RAM dejará poco espacio para las aplicaciones |
| Almacenamiento | Suficiente para SO y contenedores | SSD NVMe (para etcd en Master) | Un SSD SATA de 120 GB es suficiente para pruebas |
| Red | Conectividad de red completa | Gigabit Ethernet | Red pública o privada |
| Sistema Operativo | Linux compatible (Debian-based) | Debian 12 | - |
| Identificadores | Nombre de host, MAC, product_uuid únicos | - | - |
Actualización de Debian 12 e instalación de paquetes esenciales
Antes de iniciar cualquier instalación significativa, es una práctica fundamental asegurar que el sistema Debian 12 esté completamente actualizado. Este paso refresca las listas de paquetes y actualiza los paquetes existentes, mitigando posibles conflictos de dependencias o vulnerabilidades de seguridad.
apt update && apt upgrade
Posteriormente, se instalan los paquetes de dependencia necesarios tanto para Docker como para Kubernetes. Estos incluyen ca-certificates (para verificar conexiones SSL/TLS), curl (para transferir datos con URLs, utilizado para descargar claves GPG), gnupg (para gestionar claves GPG) y apt-transport-https (para permitir que apt obtenga paquetes a través de HTTPS). Y también los utilitarios que precisemos.
apt install mc screen rsync iptraf ccze zsh htop gnupg curl apt-transport-https ca-certificates software-properties-common
Este paso inicial es crucial porque establece una base estable y segura para la compleja instalación de Kubernetes. Al asegurar que todos los paquetes estén actualizados y que las herramientas necesarias para la gestión de repositorios y claves GPG estén presentes, se previenen de manera proactiva muchos problemas comunes relacionados con dependencias y versiones de software. Configuración de Módulos del Kernel (overlay, br_netfilter) para Persistencia
Kubernetes depende en gran medida de módulos específicos del kernel de Linux para habilitar sus funcionalidades de contenerización y red. El módulo overlay proporciona la capacidad de superposición del sistema de archivos, esencial para las imágenes y capas de contenedores. El módulo br_netfilter es crítico, ya que habilita el soporte de netfilter de puente dentro del kernel, permitiendo que iptables procese correctamente el tráfico de red puenteado, algo que Kubernetes y sus complementos de superposición de red utilizan ampliamente.
Para cargar estos módulos en la sesión actual:
modprobe overlay modprobe br_netfilter
Para asegurar que estos módulos se carguen automáticamente cada vez que el sistema se inicia, se añaden a un archivo de configuración en /etc/modules-load.d/:
cat <<EOF | tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF
Después de añadir los módulos, se verifica que estén cargados correctamente:
lsmod | egrep 'overlay|br_netfilter'
La salida debería mostrar overlay y br_netfilter listados. La necesidad explícita de estos módulos del kernel subraya la profunda integración de Kubernetes con la pila de red del kernel de Linux. Un fallo en la carga de br_netfilter en particular es una causa común de problemas de red fundamentales dentro del clúster, impidiendo que los pods se comuniquen entre sí o con servicios externos. Esto a menudo se manifiesta como errores CrashLoopBackOff para pods críticos del kube-system (por ejemplo, pods de plugins CNI, CoreDNS), lo que hace que el clúster no sea funcional y sea difícil de diagnosticar sin un conocimiento previo de este prerrequisito.
Configuración de parámetros sysctl requeridos (net.bridge.bridge-nf-call-iptables, net.ipv4.ip_forward)
Kubernetes requiere que se configuren parámetros sysctl específicos del kernel para un enrutamiento de paquetes de red y una funcionalidad de iptables adecuados dentro del clúster.
net.bridge.bridge-nf-call-iptables = 1: Este parámetro asegura que los paquetes de red que atraviesan un puente Linux (común en la red de contenedores) se pasen correctamente a iptables para su procesamiento. Esto es vital para que kube-proxy y los plugins CNI gestionen eficazmente las reglas de red de servicios y pods.
net.ipv4.ip_forward = 1: Esto habilita el reenvío de IP en el nodo, permitiendo que el kernel enrute paquetes entre diferentes interfaces de red. Esto es fundamental para la comunicación entre pods a través de los nodos y para el tráfico que fluye entre la red del host y la red de pods.
Para que estos parámetros sean persistentes, se crea un archivo de configuración en /etc/sysctl.d/ que asegura que se apliquen automáticamente al arrancar el sistema:
cat <<EOF | tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF
Para aplicar los nuevos parámetros sysctl inmediatamente sin necesidad de reiniciar el sistema, se ejecuta:
sysctl --system
Estos ajustes de sysctl no son arbitrarios; son fundamentales para la forma en que Kubernetes maneja el tráfico de red, particularmente cómo kube-proxy dirige el tráfico de servicios y cómo los plugins CNI gestionan la comunicación de pod a pod a través de los nodos. Una configuración incorrecta en este punto resultará en errores de red inalcanzable para pods y servicios, lo que efectivamente hará que el clúster sea inutilizable para alojar aplicaciones. Esta es otra área crítica donde los errores de configuración inicial pueden llevar a desafíos significativos de depuración.
Si se utiliza un firewall, se deben permitir los puertos requeridos. Por ejemplo, si usan ufw tal como fue instalado:
ufw allow 6443/tcp ufw allow 2379/tcp ufw allow 2380/tcp ufw allow 10250/tcp ufw allow 10251/tcp ufw allow 10252/tcp ufw allow 10255/tcp ufw reload
Deshabilitación permanente del swap
La documentación de Kubernetes establece explícitamente que la memoria de intercambio (swap) debe estar deshabilitada. Esto se debe a que el planificador de Kubernetes y kubelet no pueden contabilizar de manera fiable el uso de la memoria de intercambio, lo que lleva a un comportamiento impredecible de los pods, a la inanición de recursos y, potencialmente, a errores de CrashLoopBackOff para cargas de trabajo críticas. Dejar el swap habilitado puede resultar en problemas de rendimiento desconocidos y comprometer la capacidad del planificador para tomar decisiones óptimas de ubicación.
Para deshabilitar temporalmente el swap, lo que desactiva todas las particiones y archivos de intercambio actualmente activos, se utiliza el comando:
swapoff -a
Para deshabilitar permanentemente el swap, es necesario eliminar su entrada del archivo /etc/fstab, que dicta qué sistemas de archivos se montan al arrancar el sistema.
Editar el archivo /etc/fstab:
nano /etc/fstab
Se localiza y se elimina la línea que contiene la palabra swap. Esta línea suele ser /swapfile none swap sw 0 0 para un archivo de intercambio, o UUID=<your-swap-uuid> none swap sw 0 0 para una partición de intercambio. Después de eliminar la línea, se guarda y se sale del archivo (por ejemplo, Ctrl + X, luego Y, luego Enter en nano).
Si se estaba utilizando un archivo de intercambio (a diferencia de una partición de intercambio dedicada), se debe eliminar el archivo real para liberar espacio en disco:
rm /swapfile
Después de reiniciar el sistema, se puede confirmar que el swap ya no está activo con los siguientes comandos:
swapon --show # (no debería mostrar ninguna salida) free -h # (se verifica la fila 'Swap', debería mostrar 0B usado/total)
La razón principal para deshabilitar el swap es que el planificador y el Kubelet de Kubernetes no pueden gestionar de manera fiable la asignación de recursos cuando el sistema operativo está utilizando espacio de intercambio. Esto puede llevar a un comportamiento impredecible de los pods, errores de CrashLoopBackOff y una degradación severa del rendimiento, ya que el planificador podría colocar pods en nodos que parecen tener suficiente RAM pero que en realidad están haciendo un uso intensivo del swap. Este es un error común de verificación previa (Swap error en kubeadm init) que los usuarios encontrarán si no se aborda.
II. Instalación de Docker Engine
La instalación de Docker Engine es un paso esencial, ya que proporciona el tiempo de ejecución de contenedores (containerd) que Kubernetes utilizará.
Adición de la clave GPG y el repositorio oficial de Docker
Es altamente recomendable instalar Docker Engine desde su repositorio oficial en lugar de los repositorios predeterminados de Debian. La versión de Docker proporcionada en los repositorios predeterminados de Debian suele estar desactualizada y puede carecer de características o compatibilidad requeridas para los despliegues modernos de Kubernetes.
Primero, se añade la clave GPG de Docker. Esta clave se utiliza para validar la integridad y autenticidad de los paquetes de Docker que se descargan, asegurando que no hayan sido manipulados:
curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
A continuación, se añade el repositorio de Docker a la lista de fuentes de APT. Este comando añade dinámicamente el repositorio de Docker correcto para la versión de Debian (Bookworm para Debian 12) y la arquitectura del sistema:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null
Después de añadir un nuevo repositorio, es esencial actualizar el índice de paquetes del sistema para que reconozca los paquetes recién disponibles :
apt update
El uso del repositorio oficial de Docker es una práctica fundamental. Garantiza la instalación de la versión más reciente, estable y totalmente compatible de Docker Engine y sus componentes (containerd.io), lo cual es crucial para una integración sin problemas con Kubernetes y evita posibles problemas derivados de software obsoleto.
Instalación de docker-ce, docker-ce-cli y containerd.io
Con el repositorio oficial de Docker configurado, se pueden instalar los componentes necesarios de Docker Engine. Esto incluye docker-ce (el demonio de Docker Community Edition), docker-ce-cli (el cliente de línea de comandos para interactuar con Docker) y, crucialmente, containerd.io (el tiempo de ejecución de contenedores compatible con CRI con el que Kubernetes interactuará directamente).
apt install docker-ce docker-ce-cli containerd.io
Este paso instala directamente containerd.io, que, como se aclaró en la introducción, es el tiempo de ejecución real compatible con CRI que utilizará Kubernetes. Esto alinea el proceso de instalación con la arquitectura moderna de Kubernetes.
Verificación de la instalación de Docker y gestión del servicio Docker
Después de la instalación, es importante verificar que Docker Engine esté correctamente instalado y operativo.
Para verificar la instalación, se ejecuta:
docker --version
La salida debería mostrar la versión de Docker instalada (por ejemplo, Docker version 27.0.3, build 7d4bcd8).
Para asegurar que el servicio Docker se inicie automáticamente cada vez que el sistema se reinicia, se habilita el servicio:
systemctl enable docker
Si el servicio no está ya en ejecución, se debe iniciar:
systemctl start docker
Estos pasos son verificaciones estándar posteriores a la instalación y prácticas de gestión de servicios. Aseguran que Docker no solo esté instalado, sino también en ejecución y configurado para persistir después de los reinicios, lo cual es fundamental para un entorno Kubernetes estable.
Adición de usuario sin privilegios al grupo docker (opcional pero recomendado)
Por defecto, interactuar con el demonio de Docker requiere privilegios sudo. Para simplificar las operaciones diarias y evitar tener que escribir constantemente sudo antes de los comandos de Docker, es altamente recomendable añadir al usuario no root al grupo docker.
Para añadir al usuario al grupo Docker, se ejecuta (reemplazando $(whoami) con el nombre de usuario real si no se está logueado como el usuario objetivo):
usermod -aG docker $(whoami)
Para que la nueva membresía de grupo tenga efecto en la sesión actual, es necesario cerrar la sesión y volver a iniciarla, o ejecutar el comando newgrp:
newgrp docker
Este paso mejora significativamente la experiencia del usuario al permitir la interacción directa con Docker sin privilegios elevados. Aunque es opcional, es una mejora común en la calidad de vida para desarrolladores y administradores que trabajan frecuentemente con contenedores, y también una buena práctica de seguridad para evitar el acceso constante como root.
III. Configuración del tiempo de ejecución de contenedores y kubelet para Kubernetes
La correcta configuración de los controladores de cgroup es un aspecto crítico para la estabilidad de un clúster de Kubernetes.
Comprensión de los controladores cgroup (systemd vs. cgroupfs)
Los cgroups (control groups) son una característica del kernel de Linux que permite la asignación, priorización y gestión de recursos del sistema (CPU, memoria, E/S de disco, red) entre grupos de procesos. Tanto containerd (el runtime de contenedores) como kubelet (el agente que se ejecuta en cada nodo de Kubernetes) interactúan con los cgroups para aplicar límites de recursos y gestionar los procesos de los contenedores.
Kubernetes recomienda encarecidamente configurar tanto el runtime de contenedores como kubelet para que utilicen el controlador cgroup de systemd, en lugar del controlador cgroupfs predeterminado de kubelet. Esta recomendación se debe a que kubeadm gestiona kubelet como un servicio de systemd, y systemd en sí mismo está estrechamente integrado con los cgroups.
Un requisito crítico es que tanto el runtime de contenedores (containerd en esta configuración) como kubelet estén configurados para utilizar el mismo controlador cgroup. Una falta de coincidencia entre estos controladores es una causa muy común e insidiosa de inestabilidad del clúster, lo que con frecuencia lleva a problemas como errores de CrashLoopBackOff para pods críticos del kube-system (por ejemplo, CoreDNS, plugins CNI) y una gestión de recursos poco fiable.
La falta de coincidencia del controlador cgroup es un problema común, sutil y a menudo frustrante para las nuevas instalaciones de Kubernetes. Representa una interdependencia técnica profunda entre la gestión de recursos del kernel de Linux, el runtime de contenedores elegido y el agente de orquestación de Kubernetes (kubelet). La recomendación para systemd no es arbitraria, sino una consecuencia directa del diseño de kubeadm, que aprovecha systemd para la gestión de kubelet. Pasar por alto esta alineación conduce a una inestabilidad fundamental del clúster, donde el aislamiento de recursos se rompe y los pods críticos del kube-system no se inicializan correctamente, lo que hace que el clúster sea inutilizable. Configuración de containerd para usar el controlador cgroup de systemd
Por defecto, containerd podría utilizar cgroupfs como su controlador cgroup. Para alinearse con el controlador systemd de kubelet (especialmente para configuraciones basadas en kubeadm), se debe configurar explícitamente containerd para que utilice systemd.
Primero, si no existe ya, se genera un archivo de configuración predeterminado de containerd:
mkdir -p /etc/containerd containerd config default | tee /etc/containerd/config.toml
Luego, se edita el archivo /etc/containerd/config.toml. Se localiza la sección [plugins.“io.containerd.grpc.v1.cri”.containerd.runtimes.runc.options] y se cambia el valor de SystemdCgroup de false a true.
Se puede usar sed:
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
Finalmente, para que los cambios de configuración surtan efecto, el servicio containerd debe reiniciarse:
systemctl restart containerd
Este es el paso necesario para asegurar que el controlador cgroup de containerd esté configurado en systemd, resolviendo así posibles desajustes con kubelet y previniendo problemas comunes de CrashLoopBackOff.
Asegurar que Kubelet utilice el controlador cgroup de systemd (predeterminado para kubeadm v1.22+)
Para las versiones de Kubernetes 1.22 y posteriores, kubeadm está diseñado para que el cgroupDriver de kubelet sea systemd por defecto si no se establece explícitamente en la KubeletConfiguration. Esto simplifica la configuración para las instalaciones más recientes.
Sin embargo, generalmente se considera una buena práctica definir explícitamente cgroupDriver: systemd dentro de un archivo de configuración de kubeadm (por ejemplo, kubeadm-config.yaml) al inicializar el clúster. Esto proporciona claridad, asegura la coherencia en despliegues automatizados y previene posibles cambios no deseados durante futuras actualizaciones de kubeadm, especialmente si se está migrando desde una configuración anterior que podría haber utilizado cgroupfs.
Un ejemplo de fragmento de kubeadm-config.yaml para una configuración explícita es:
# kubeadm-config.yaml kind: ClusterConfiguration apiVersion: kubeadm.k8s.io/v1beta4 kubernetesVersion: v1.29.0 # Ajustar a la versión deseada de Kubernetes --- kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 cgroupDriver: systemd
Este archivo se pasaría luego a kubeadm init utilizando el modificador –config.
Aunque el comportamiento predeterminado de kubeadm para el controlador cgroup de kubelet simplifica la configuración inicial para las versiones más recientes, definir explícitamente cgroupDriver: systemd en un archivo kubeadm-config.yaml eleva la configuración de una dependencia implícita de los valores predeterminados a una infraestructura como código explícita y controlada por versiones. Este enfoque proactivo mejora la claridad de la configuración, asegura la coherencia en los despliegues y actúa como una salvaguarda contra posibles cambios o regresiones no deseados durante futuras actualizaciones de Kubernetes, lo cual es un aspecto clave de una gestión robusta del sistema.
IV. Instalación de componentes de Kubernetes (kubeadm, kubelet, kubectl)
Los componentes principales de Kubernetes son esenciales para la gestión del clúster. Adición del Repositorio APT de Kubernetes y la Clave GPG
Las herramientas principales de Kubernetes (kubeadm, kubelet, kubectl) no están disponibles en los repositorios predeterminados de Debian. Es necesario añadir el repositorio oficial de Kubernetes APT al sistema para instalarlas.
Primero, se añade la clave GPG de Kubernetes. Esta clave se utiliza para autenticar los paquetes de Kubernetes:
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.33/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
(Nota: Reemplazar v1.33 con la versión deseada de Kubernetes o stable para la última versión estable. Se recomienda utilizar una versión específica para mayor consistencia.)
Luego, se añade el repositorio APT de Kubernetes:
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /' | tee /etc/apt/sources.list.d/kubernetes.list
(De nuevo, ajustar v1.33 según sea necesario.)
Finalmente, se actualiza el índice de paquetes del sistema para incluir los nuevos paquetes de Kubernetes:
apt update
Instalación de kubeadm, kubelet y kubectl
Estas tres herramientas binarias son fundamentales para desplegar y gestionar el clúster de Kubernetes:
- kubeadm: Una herramienta para arrancar clústeres de Kubernetes siguiendo las mejores prácticas
- kubelet: El agente que se ejecuta en cada nodo del clúster, asegurando que los contenedores se ejecuten en un pod
- kubectl: La herramienta de línea de comandos para ejecutar comandos contra clústeres de Kubernetes
El comando para la instalación es:
apt install kubeadm kubelet kubectl
Este paso instala los componentes centrales que permiten la creación del clúster, la gestión de nodos y la interacción del usuario con Kubernetes. Sin estos, un clúster de Kubernetes no puede formarse ni gestionarse.
Retención de versiones de paquetes para prevenir actualizaciones accidentales
Una vez que kubeadm, kubelet y kubectl están instalados, es críticamente importante “retener” sus versiones. Kubernetes tiene políticas estrictas de desviación de versiones (por ejemplo, kubelet no debe tener más de dos versiones menores de antigüedad o ser más reciente que el kube-apiserver, y kubectl debe estar dentro de una versión menor). Una actualización apt upgrade accidental podría actualizar estos paquetes a versiones incompatibles, lo que llevaría a la inestabilidad del clúster, fallos de comunicación o incluso un colapso completo del clúster. La retención asegura que las versiones permanezcan fijas, evitando interrupciones no deseadas.
Para retener las versiones de los paquetes, se utiliza el siguiente comando:
apt-mark hold kubeadm kubelet kubectl
Este paso es vital para la estabilidad y el mantenimiento a largo plazo del clúster de Kubernetes. Al “retener” las versiones de estos componentes críticos, se previene que las actualizaciones automáticas o accidentales de paquetes rompan la compatibilidad del clúster, lo que podría resultar en fallos operacionales significativos y difíciles de diagnosticar.
V. Inicialización del Control Plane de Kubernetes (Nodo Master)
La inicialización del plano de control es el primer paso para establecer el clúster de Kubernetes.
Elección de un CIDR de red de pods
Antes de inicializar el plano de control, es necesario elegir un classless inter-domain routing (CIDR) para la red de pods. Este rango de direcciones IP se utilizará exclusivamente para los pods dentro del clúster y es fundamental para la comunicación entre ellos.
Algunos CIDRs comunes utilizados por los plugins CNI (Container Network Interface) incluyen:
- 10.244.0.0/16: Comúnmente utilizado con Flannel.
- 192.168.0.0/16: Comúnmente utilizado con Calico.
Es crucial que el CIDR elegido no se superponga con ninguna red existente en la infraestructura para evitar conflictos de enrutamiento.
Inicialización del Plano de Control con kubeadm init
El comando kubeadm init es el encargado de arrancar el nodo Master del clúster de Kubernetes. Realiza una serie de verificaciones previas para validar el estado del sistema y luego procede a configurar los componentes del plano de control, generar certificados y establecer la configuración inicial del clúster.
Para inicializar el plano de control, se utiliza el siguiente comando. Se debe reemplazar <dirección_ip_del_servidor_api> con la dirección IP de la máquina donde se está instalando el nodo Master. El pod-network-cidr debe coincidir con el rango elegido para el plugin CNI que se instalará posteriormente. Si el swap no se deshabilitó previamente, se puede añadir –ignore-preflight-errors=Swap para continuar, aunque no es lo recomendado :
kubeadm init --apiserver-advertise-address <dirección_ip_del_servidor_api> --pod-network-cidr <su_pod_network_cidr>
Ejemplo:
kubeadm init --apiserver-advertise-address 192.168.1.100 --pod-network-cidr 10.244.0.0/16
La salida de este comando proporcionará información crucial, incluyendo los pasos para configurar kubectl y el comando kubeadm join necesario para que los nodos worker se unan al clúster. Es vital guardar esta salida, ya que contiene el token y el hash del certificado CA necesarios para la unión de nodos.
Configuración del acceso a kubectl para usuarios no privilegiados
Después de la inicialización del clúster, kubectl necesita un archivo de configuración (kubeconfig) para poder comunicarse con el clúster de Kubernetes. Este archivo, admin.conf, se genera en /etc/kubernetes/ y contiene las credenciales de administrador para el clúster.
Para configurar el acceso de kubectl para un usuario no root, se copian los archivos de configuración y se ajustan los permisos:
mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config
Para que kubectl utilice este archivo de configuración en la sesión actual, se exporta la variable de entorno KUBECONFIG:
export KUBECONFIG=$HOME/.kube/config
Para hacer que esta configuración sea persistente en futuras sesiones, se puede añadir la línea export KUBECONFIG=$HOME/.kube/config al archivo ~/.bashrc o ~/.profile del usuario.
Estos pasos son fundamentales para permitir que un usuario interactúe con el clúster de Kubernetes utilizando kubectl. Sin esta configuración, kubectl no podrá localizar ni autenticarse con el servidor API del clúster.
Eliminación del taint del nodo Master (opcional para clústeres de un solo nodo)
Por defecto, kubeadm aplica un “taint” al nodo Master (node-role.kubernetes.io/control-plane:NoSchedule). Este taint evita que los pods de carga de trabajo se programen en el nodo Master, reservándolo para los componentes del plano de control. En un clúster de producción con múltiples nodos Worker, esto es deseable. Sin embargo, para un clúster de un solo nodo (donde el nodo Master también actuará como nodo Worker), este taint debe eliminarse para permitir que las cargas de trabajo se ejecuten en él.
Para eliminar el taint del nodo Master, se utiliza el siguiente comando (reemplazando <nombre_del_nodo_master> con el nombre real del nodo, que se puede obtener con kubectl get nodes):
kubectl taint nodes <nombre_del_nodo_master> node-role.kubernetes.io/control-plane:NoSchedule-
Este paso es opcional y depende del diseño del clúster. Si se planea tener un clúster con nodos Worker dedicados, este paso no es necesario.
VI. Instalación de un plugin de Container Network Interface (CNI)
Un plugin CNI es un componente indispensable para el funcionamiento de la red de pods en Kubernetes.
Importancia de CNI
Kubernetes requiere un plugin CNI para habilitar la red de pods y la comunicación entre ellos. Sin un plugin CNI instalado y configurado, los pods no podrán comunicarse entre sí, ni con el plano de control, ni con servicios externos. Esto se manifestará comúnmente con pods de CoreDNS y otros componentes del kube-system que permanecerán en estado Pending o CrashLoopBackOff.
Elección de un Plugin CNI (Flannel vs. Calico)
Existen varios plugins CNI disponibles, cada uno con sus propias características y casos de uso. Dos de los más populares son Flannel y Calico:
- Flannel: Es un tejido de red de capa 3 simple y ligero para Kubernetes. Flannel gestiona una red IPv4 entre múltiples nodos en un clúster. Es conocido por su simplicidad y buen rendimiento para la conectividad básica. Sin embargo, carece de características avanzadas como las políticas de red. Es una excelente opción para clústeres simples o entornos de prueba.
- Calico: Ofrece características más avanzadas, incluyendo políticas de red robustas que permiten un control granular sobre el tráfico entre pods, servicios y puntos finales externos. Calico es más complejo de configurar que Flannel, pero es preferido para entornos de producción que requieren seguridad de red avanzada y capacidades de aislamiento.
La elección entre Flannel y Calico depende de los requisitos específicos del clúster. Flannel es adecuado para clústeres que solo necesitan conectividad básica y no requieren políticas de red avanzadas, mientras que Calico es la opción preferida para clústeres que necesitan características de seguridad de red y aislamiento más sofisticadas.
Pasos de Instalación (Ejemplo con Flannel)
Para instalar Flannel, se utiliza un manifiesto YAML que configura el plugin CNI en el clúster. Es crucial que el pod-network-cidr especificado en el comando kubeadm init coincida con el CIDR configurado en el manifiesto de Flannel. El CIDR predeterminado de Flannel es 10.244.0.0/16.
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
Después de aplicar el manifiesto, los pods de Flannel se desplegarán en el espacio de nombres kube-system. Se puede verificar su estado con kubectl get pods -n kube-system.
Pasos de Instalación (Ejemplo con Calico)
Para Calico, se recomienda el método del operador para gestionar la instalación y el ciclo de vida. Calico también detectará automáticamente el pod-network-cidr si se utiliza kubeadm.
Instalar el operador Tigera y las definiciones de recursos personalizados (CRDs):
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.30.1/manifests/operator-crds.yaml kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.30.1/manifests/tigera-operator.yaml
Descargar los recursos personalizados necesarios para configurar Calico:
curl https://raw.githubusercontent.com/projectcalico/calico/v3.30.1/manifests/custom-resources.yaml -O
Se puede personalizar este manifiesto custom-resources.yaml localmente si se desea modificar la instalación de Calico.
Crear el manifiesto para instalar Calico:
kubectl create -f custom-resources.yaml
Después de aplicar los manifiestos, se puede verificar la instalación de Calico:
watch kubectl get pods -n calico-system
Se debería ver una salida similar a:
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-node-txngh 1/1 Running 0 54s
VII. Verificación del estado y salud del clúster
Una vez que todos los componentes están instalados, es fundamental verificar la salud y el estado operativo del clúster de Kubernetes.
Verificación de componentes clave
Se utilizan varios comandos kubectl para inspeccionar el estado de los diferentes componentes del clúster:
Verificar el estado de los nodos:
kubectl get nodes
La salida debería mostrar que todos los nodos tienen el estado Ready. Si un nodo muestra NotReady, se puede obtener información detallada con kubectl describe node <nombre_del_nodo> para examinar las secciones Conditions y Events.
Verificar el estado de los pods del sistema:
kubectl get pods -n kube-system
Todos los pods en el espacio de nombres kube-system (incluidos coredns, kube-proxy, etcd, kube-apiserver, kube-controller-manager, kube-scheduler y el plugin CNI) deberían estar en estado Running y Ready.
Obtener información básica del clúster:
kubectl cluster-info
Este comando proporciona información sobre el plano de control y el servidor CoreDNS.
Verificar la versión del cliente y del servidor:
kubectl version
Es crucial que las versiones del cliente (kubectl) y del servidor (clúster) sean compatibles. Una diferencia de versión superior a +/-1 minor version puede generar advertencias o problemas.
Verificar el estado de los componentes del plano de control:
kubectl get componentstatuses
Las columnas STATUS y MESSAGE deberían mostrar Healthy y ok para los componentes del plano de control.
Ver eventos del clúster para solucionar problemas:
kubectl get events -A
Los eventos proporcionan un registro de las actividades y posibles problemas dentro del clúster, lo cual es invaluable para la depuración.
Solución de problemas comunes
Durante la verificación, se pueden encontrar algunos problemas comunes:
Pods en estado CrashLoopBackOff: Este estado a menudo indica un problema con la configuración del tiempo de ejecución de contenedores (por ejemplo, una falta de coincidencia del controlador cgroup entre containerd y kubelet) o problemas con el plugin CNI. Se deben revisar los logs del pod (kubectl logs <nombre_del_pod> -n <namespace>) y los eventos del pod (kubectl describe pod <nombre_del_pod> -n <namespace>) para obtener más detalles.
Nodos en estado NotReady: Esto puede deberse a problemas de red, presión de memoria o disco, o problemas con el kubelet. Se utiliza kubectl describe node <nombre_del_nodo> para inspeccionar las secciones Conditions y Events del nodo, que proporcionarán pistas sobre la causa raíz.
Pods en estado Pending: Generalmente indica que el planificador no puede encontrar un nodo adecuado para el pod, a menudo debido a restricciones de recursos (CPU, memoria) o porque el plugin CNI aún no está completamente operativo.
La revisión sistemática de estos estados y eventos es fundamental para asegurar un clúster de Kubernetes funcional y estable.
VIII. Conclusiones y recomendaciones
La configuración de Kubernetes con Docker (a través de containerd) en Debian 12 es un proceso que requiere atención a los detalles y una comprensión de las interdependencias entre el sistema operativo, el tiempo de ejecución de contenedores y los componentes de Kubernetes. La adherencia a las mejores prácticas y los requisitos específicos, como la deshabilitación del swap y la alineación del controlador cgroup, es fundamental para la estabilidad y el rendimiento del clúster.
La transición de Kubernetes para no usar directamente Docker Engine a favor de la Interfaz de Tiempo de Ejecución de Contenedores (CRI) y containerd es un cambio arquitectónico significativo. Este cambio, aunque puede generar confusión inicial si no se explica, es una evolución natural hacia una mayor modularidad y estandarización dentro del ecosistema de contenedores. Comprender que containerd es el tiempo de ejecución real que Kubernetes utiliza, incluso cuando se instala Docker Engine, es clave para una configuración exitosa y una resolución de problemas eficaz.
La importancia de los prerrequisitos del sistema, como la configuración de los módulos del kernel (overlay, br_netfilter) y los parámetros sysctl (net.bridge.bridge-nf-call-iptables, net.ipv4.ip_forward), no puede subestimarse. Estos ajustes a nivel del sistema operativo son la base sobre la cual se construye la red de Kubernetes, y su configuración incorrecta es una causa frecuente de fallos de red difíciles de diagnosticar. De manera similar, la estricta necesidad de deshabilitar el swap y asegurar que containerd y kubelet utilicen el mismo controlador cgroup (systemd) aborda problemas fundamentales de gestión de recursos que, de otro modo, conducirían a la inestabilidad del clúster y a un comportamiento impredecible de los pods.
Para futuras implementaciones y entornos de producción, se recomienda considerar las siguientes acciones:
- Clústeres Multi-Nodo: Para alta disponibilidad y escalabilidad, se debe planificar la adición de nodos Worker al clúster utilizando el comando kubeadm join generado durante la inicialización del Master.
- Almacenamiento Persistente: Para cargas de trabajo con estado, es esencial configurar soluciones de almacenamiento persistente (por ejemplo, volúmenes persistentes con un aprovisionador de almacenamiento) para asegurar que los datos no se pierdan si los pods se reinician o se mueven.
- Monitoreo y Logging: Implementar soluciones robustas de monitoreo (como Prometheus y Grafana) y logging centralizado (como ELK Stack o Loki) es crucial para la observabilidad del clúster y la resolución proactiva de problemas.
- Seguridad: Revisar y aplicar políticas de seguridad de red (utilizando las capacidades del CNI elegido, como Calico), configurar el control de acceso basado en roles (RBAC) y asegurar los componentes del clúster son pasos vitales para un entorno de producción.
- Automatización: Para despliegues a gran escala o frecuentes, se recomienda automatizar el proceso de configuración utilizando herramientas como Ansible, Terraform o scripts personalizados para asegurar la consistencia y reducir el error humano.
Bibliografía
- Documentación de Kubernetes: https://kubernetes.io/docs/home/
- Kubernetes Debugging: https://lumigo.io/kubernetes-monitoring/kubernetes-debugging/
- How to Install Docker on Debian 12: https://greenwebpage.com/community/how-to-install-docker-on-debian-12/
- K3s: basic network options: https://docs.k3s.io/networking/basic-network-options
- CNI with Flannel: https://ubuntu.com/kubernetes/charmed-k8s/docs/cni-flannel
- How to install Docker in Debian 12: https://docs.vultr.com/how-to-install-docker-on-debian-12
- Calico Quickstart Guide: https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
- Installing and configuring containerd as a Kubernetes Container Runtime: https://www.nocentino.com/posts/2021-12-27-installing-and-configuring-containerd-as-a-kubernetes-container-runtime/